Orders of Algorithms
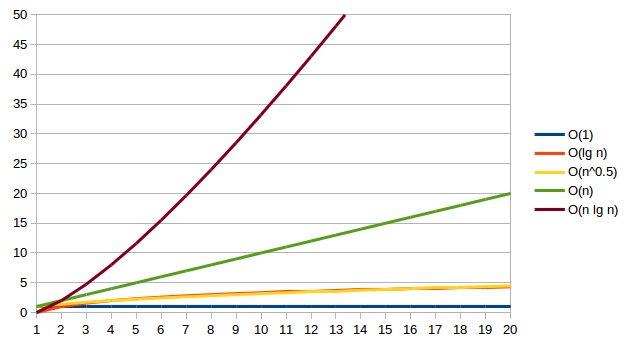
- Constant:
O(1) - Sub-linear:
O(lg n) - Linear:
O(n) - Supralinear:
O(n lg n)
Constant means that the algorithm is independent of input size (say indexing into an array). Algorithms that repeated divide their input in half generate a logarithmic order. Examples include binary search, and tree search algorithms. A linear algorithm is one that performs a constant amount of work for each item in the input.
The most familiar O(n log n) algorithms are sort
algorithms like quicksort, heapsort, or merge sort.
Orders of Algorithms, supralinear
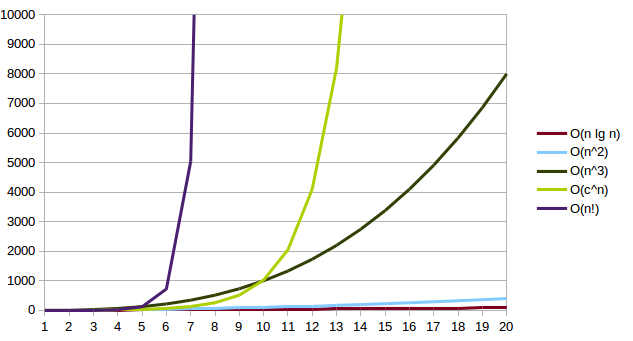
O(n2)O(nc)where c > 1O(cn)O(n!)
All of the O(nc) algorithms are pretty easy to
recognize. Look for nested loops over the input.
The O(cn) are most often found in public
key cryptography. Any time you need to work on permutations of a data
set, you get into the realm of O(n!). These more complex
algorithms are things that you really want to avoid for large data
sets.
Details of Fibonnaci Example
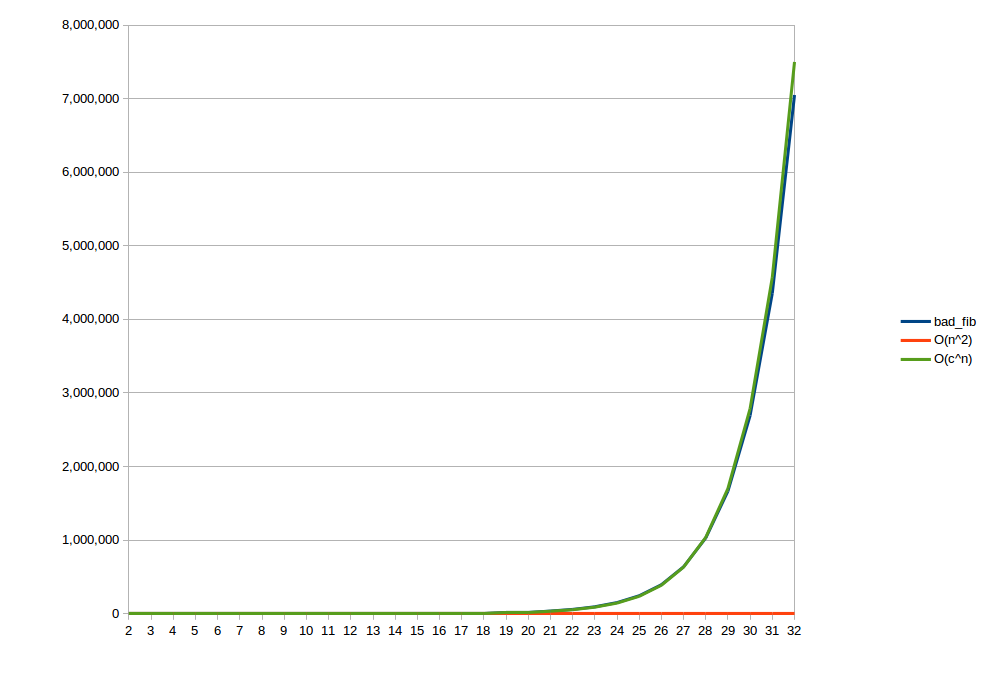
| n | bad | good | O(n2) | O(1.64n) |
|---|---|---|---|---|
| 2 | 3 | 2 | 4 | 3 |
| 3 | 5 | 3 | 9 | 4 |
| 4 | 9 | 3 | 16 | 7 |
| ... | ... | ... | ... | ... |
| 10 | 177 | 10 | 100 | 141 |
| 11 | 287 | 11 | 121 | 231 |
| ... | ... | ... | ... | ... |
| 20 | 21,891 | 20 | 400 | 19,810 |
| ... | ... | ... | ... | ... |
| 31 | 4,356,617 | 31 | 961 | 4,572,559 |
| 32 | 7,049,155 | 32 | 1,024 | 7,498,996 |
This shows some of the measurements I used to work out the order of the fibonacci algorithm. I mostly played around with numbers and eyeballed the curve fit.